
Datenabfragen mit GraphQL
Bist du bereit für die Zukunft der API-Kommunikation?
Ein Fachbeitrag von Daniel Ackermann & Tobias Surmann aus dem Segment Finance & Public
Du willst maximale Effizienz und Flexibilität in der API-Kommunikation und suchst nach einer Alternative zu REST? Dann könnte GraphQL die Lösung für dich sein.
Das erwartet Sie in diesem Artikel:
Was ist GraphQL?
GraphQL ist eine Datenabfrage- und Datenmanipulationssprache für APIs und spezifiziert gleichzeitig auch das Laufzeitsystem, um diese Abfragen zu erfüllen. Es existiert eine Vielzahl von entsprechenden Open-Source-Implementierungen für verschiedene Programmiersprachen und Technologien (sowohl für die Client- als auch die Serverseite), die die Spezifikation umsetzen (bspw. Apollo, vue-apollo oder GraphQL Spring Boot Starter).
Mittlerweile setzen viele bekannte Unternehmen GraphQL aktiv ein, z. B. Twitter, shopify, Meta, GitHub oder PayPal.
GraphQL wird gerne mit dem Architekturstil REST verglichen und als eine bessere Alternative dargestellt, löst es doch einige bekannte Probleme wie das Over- und Underfetching. Zudem ist REST zwar stark etabliert in der Industrie, doch bietet es weitaus weniger Flexibilität als GraphQL.
Wie funktioniert GraphQL?
Clients rufen benötige Daten in der Regel über eine API von einem Backend-Server ab. Dies lässt sich durch verschiedene Technologien umsetzen, eine davon ist GraphQL. Mit Hilfe von GraphQL ist ein Client in der Lage, mittels einer einzigen Anfrage genau jene Daten anzufordern, die er benötigt – ohne dabei zu viele oder zu wenige Daten zu erhalten.
Eine GraphQL-API stellt für gewöhnlich lediglich einen einzigen Endpunkt zur Kommunikation mit dem Client zur Verfügung. Um Daten vom Server anzufragen, schickt der Client eine Query an den Endpunkt des Servers. In der Query spezifiziert der Client genau, welche Daten er erhalten möchte. Diese Query trifft dann auf einen Resolver im GraphQL-Server. Der Resolver sammelt die benötigten Daten und schickt sie an den Client zurück. Um Daten auf dem Server zu bearbeiten, schickt der Client eine Mutation an den Endpunkt, die ebenfalls auf einen passenden Resolver trifft. Der Resolver kümmert sich um die Änderungen und schickt eine passende Antwort an den Client zurück.
Bei GraphQL handelt sich um ein Konzept, somit funktioniert es unabhängig von eingesetzten Technologien, Programmiersprachen oder Datenbanken.
Beispiel für eine Anwendung von GraphQL
Der Server definiert ein Schema, dem alle darüber zur Verfügung gestellten Daten genügen. Die Syntax, in der das Schema geschrieben wird, heißt Schema Definition Language (SDL). In dem nachfolgenden Beispiel sind in der Datenquelle zwei Entitäten vorhanden, eine Person und ein Post.
Eine Person kann mehrere Posts erstellen und ein Post besitzt immer einen Autor bzw. eine Autorin. Diese Entitäten würden im Schema als zwei Objekttypen dargestellt werden. Ein Typ besteht aus einem Namen und streng typisierten Datenfeldern. Das Ausrufezeichen hinter dem Typ bedeutet, dass das Feld nicht null sein darf.
type Person {
id: ID!
name: String!
age: Int!
posts: [Post!]!
}
type Post {
id: ID!
title: String!
author: Person!
}
Um die definierten Typen abfragen zu können, müssen im Schema Queries definiert werden. Sendet ein Client eine Query an den Server, dann erhält er als Antwort das Objekt, was hinter dem Doppelpunkt der Query steht. Eckige Klammern bedeuten, dass eine Liste aus mehreren Objekten zurückgegeben wird.
type Query {
person(id: ID!): Person!
post(id: ID!): Post!
allPersons: [Person]!
allPosts: [Post]!
}
Der Client spricht den Server an und schickt in der Anfrage eine Query mit, die genau die Felder referenziert, die zurückgeliefert werden sollen.
query {
allPersons {
name
age
}
}
Jetzt weiß der Server, welche Daten der Client erhalten möchte. Der Server implementiert sogenannte Resolver, um diese Abfrage zu erfüllen. Jede Query trifft auf genau einen Resolver, der alle angefragten Daten aus der Datenbank holt und in einer Datenstruktur zurückgibt. Im obigen Beispiel würde die Query „allPersons“ auf einen Resolver treffen, dieser sammelt alle Personen aus der Datenbank und gibt sie in einer geeigneten Datenstruktur an den Client zurück. Da in der Query lediglich die Felder „name“ und „age“ einer Person angefragt wurden, wird das Feld „posts“ nicht mitgeschickt, wodurch sowohl die Auslastung des Servers als auch die des Netzwerks verringert werden.
GraphQL vs. REST: Wo liegen die Unterschiede?
Der wesentliche Unterschied zwischen beiden Technologien ist die Art, wie Daten vom Client angefragt und wie sie ihm zurückgeliefert werden. Eine REST-API definiert für jeden denkbaren Anwendungsfall einen eigenen Endpunkt. Es müssen DTOs erstellt werden und die Daten werden genauso zurückgeliefert, wie der Service es definiert hat.
Die Resolver von GraphQL erlauben es dem Client ebenfalls Daten anzufragen, lassen sich aber viel flexibler nutzen: Der Client entscheidet, welche Daten geliefert werden und nicht der Server. Eine REST-API ist somit eher Server-driven und eine GraphQL-API Client-driven.
Die Vorteile von GraphQL im Detail
Kein Overfetching: Overfetching entsteht, wenn der Client spezifische Daten anfordern möchte, der Server aber keine Möglichkeit bietet, genau diese Daten zu erhalten. Jeder Endpunkt liefert also mehr Daten zurück, als vom Client benötigt werden. Dabei entsteht eine höhere Netzauslastung. Das ist ein häufiges Problem einer REST-API. GraphQL löst dieses Problem durch Resolver. Der Client schickt eine Query an den Server und spezifiziert genau die Felder, die er benötigt. Der Resolver, auf den die Query trifft, sammelt alle angefragten Daten aus der Datenbank und liefert dem Client nur die Daten zurück, die in der Query angegeben wurden. Somit wird eine hohe Flexibilität geboten, Netzwerkauslastung verringert und Overfetching vermieden.
Kein Underfetching: Underfetching entsteht, wenn es keine Möglichkeit gibt, mittels einer einzigen Anfrage alle benötigten Daten abzufragen. Im Rahmen von REST geschieht dies, wenn der Client mehrere Endpunkte ansprechen muss, um alle benötigten Daten zu erhalten. Beim Einsatz von GraphQL hängen alle Objekttypen gemäß Schema über einen Graphen miteinander zusammen. Somit kann der Client mittels einer Abfrage alle Objekttypen sowie die zugehörigen Felder erreichen, wodurch das Underfetching vermieden wird.
Introspection: Im GraphQL-Schema werden alle Objekttypen, Queries und Mutations definiert. GraphQL bietet einige vordefinierte Queries, die Informationen über das Schema liefern. Darauf basieren viele Tools, die in der Entwicklung sehr nützlich sind (IntelliJ Plugin, autocomplete, code generation, GraphiQL, Playground u.v.m.). In einer Produktionsumgebung sollte die Introspection dennoch deaktiviert und durch eine Dokumentation ersetzt werden, um die Kontrolle darüber zu behalten, welche Informationen über das Schema nach außen preisgegeben werden.
Versionierung: Eine API wird sich über die Zeit ihrer Nutzung weiterentwickeln, um neue Herausforderungen zu lösen oder auf neue Wünsche der Kunden zu reagieren. Neue Felder und Typen können dabei problemlos integriert werden. Anders sieht es beispielsweise beim Umbenennen von aktuellen Feldern aus. Die Clients müssten sich in diesem Fall selbst anpassen, um das alte Feld noch ansprechen zu können. Dabei würden im ersten Moment sämtliche Clients, die die API nutzen, ausfallen. Bei solchen „breaking changes“ würde man in einer REST-API einen neuen Endpunkt definieren. Der alte Endpunkt dürfte aber nicht gelöscht werden, weil alte Clients ggf. noch auf diesen Endpunkt zugreifen. Dadurch wird die Übersichtlichkeit und die Wartbarkeit beeinträchtigt.
GraphQL kann grundsätzlich genauso versioniert werden wie eine REST-API. Ein besserer Weg ist jedoch eine API-Evolution durch einen versionslosen Ansatz. Sobald es zu einer Änderung im Schema kommt, wird das geänderte Feld durch eine Annotation als „deprecated“ markiert und ein neues Feld definiert, welches die Änderung enthält. Außerdem kann das alte Feld mit einer Begründung versehen werden, die dem Client verrät, wieso es eine Änderung gab und wo das neue Feld zu finden ist. So können Clients weiterarbeiten, die das alte Feld noch nutzen. Durch das Loggen von Queries lässt sich beobachten, ob ein Feld nicht mehr in Benutzung ist. Sobald dann alle Clients den Wechsel zum neuen Feld gemacht haben, kann das alte Feld problemlos entfernt werden.
# Old Version
type Person {
id: ID!
name: String!
age: Int!
posts: [Post!]!
}
# New Version
type Person {
id: ID!
name: String! @deprecated(reason: "Changed to 'firstname' and 'lastname'")
firstname: String!
lastname: String!
age: Int!
posts: [Post!]!
}
Einsatzgebiete von GraphQL
GraphQL glänzt besonders, wenn Clients viele unterschiedliche Datenrepräsentationen zu einer Ressource benötigen. Gerade bei langsamen Netzwerkverbindungen (z. B. im Bereich IoT und Mobile Apps) profitiert GraphQL durch die Vermeidung von Under- und Overfetching.
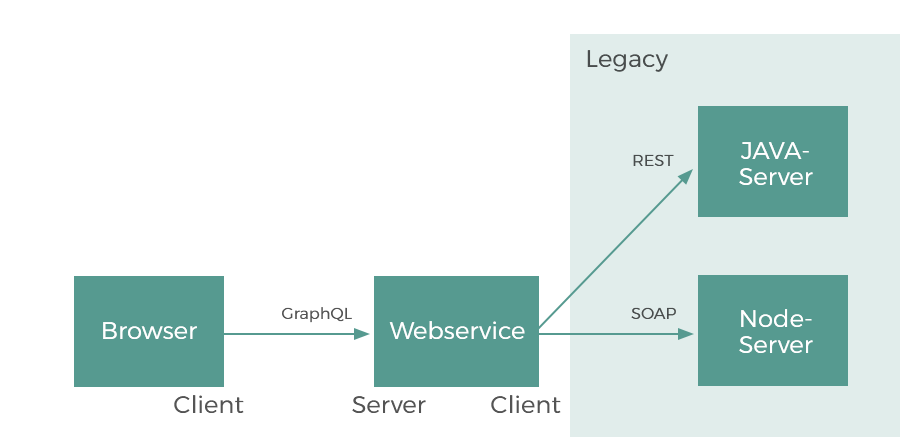
Außerdem lässt sich GraphQL als Schnittstelle zwischen Clients und anderen Legacy-Anwendungen nutzen. Somit erhalten Clients einen effizienten und einheitlichen Zugriff auf die API mittels GraphQL, während der GraphQL-Server als API-Gateway mit den dahinterliegenden Anwendungen kommuniziert.
Fazit
GraphQL löst einige große Herausforderungen, die im Kontext von REST-Architekturen auftreten und kann daher durchaus die Zukunft der API-Kommunikation bedeuten. Zu den bedeutsamsten Vorteilen von GraphQL gehören eine hohe Flexibilität und Effizienz bei der Datenabfrage.
Im direkten Vergleich ist das Aufsetzen einer GraphQL-API aufwändiger als bei einer REST-API, da zu Beginn ein initiales GraphQL-Schema erstellt werden muss. GraphQL erfordert in der Regel zunächst einen höheren Lernaufwand, da die meisten Entwicklerinnen und Entwickler eher mit REST vertraut sind. Dafür ist die Netzauslastung mit GraphQL deutlich geringer, was im Bereich der mobilen Anwendung eine große Rolle spielt. Es kommt also ganz auf den Anwendungsfall an, welche Technologie die passendere ist.
Bei weiteren Fragen rund um GraphQL kontaktieren Sie uns gern.

Phillip Conrad
Segment Manager | Finance & Public
p.conrad@smf.de
Weiterführende Links


