
Apache Kafka – Ein Überblick
Ein Fachbeitrag von Tobias Surmann aus dem Segment Finance & Public
Apache Kafka ist aus der Welt der Echtzeitdatenverarbeitung nicht mehr wegzudenken – längst ist die Plattform zum Rückgrat moderner (Daten-)Architekturen erwachsen. Dieser Artikel gibt einen einordnenden Überblick über die Grundlagen von Apache Kafka und zeigt die vielfältigen Anwendungsmöglichkeiten auf.
Das erwartet Sie in diesem Artikel:
Was ist Apache Kafka?
Apache Kafka ist eine Event-Streaming-Plattform, die seit 2011 als Open-Source-Software von der Apache Software Foundation getragen wird. Kafka ist unter der Apache 2.0 Lizenz verfügbar, sodass ein Einsatz im kommerziellen Kontext möglich ist. Apache Kafka hat sich als De-facto-Standard für die Echtzeitverarbeitung von Daten am Markt etabliert. Gemäß eigener Aussage setzen über 80% der umsatzstärksten US-Firmen Kafka ein.
Die Entwicklung von Apache Kafka wurde ursprünglich bei LinkedIn gestartet. Herausforderung war das schnelle Datenwachstum im Unternehmen (Big Data), sodass Daten effizient und in Echtzeit verarbeitet werden mussten (konkret: Daten zu Benutzeraktivitäten, Log-Daten sowie Daten zu Server- und Netzwerkmetriken).
Kafka wurde als verteiltes System konzipiert und lässt sich mittlerweile auf beliebiger Hardware, über VMs oder Container horizontal skalieren. Auf diese Weise kann ein Kafka-Cluster kosteneffizient erweitert werden. Darüber hinaus war ein hoher Datendurchsatz essenziell, welcher im Wesentlichen durch verteilte Verarbeitung und Parallelisierung erreicht wird. Ein weiterer signifikanter Vorteil von Kafka ist die Zuverlässigkeit des Systems. Replikation und Redundanz führen zu einer hohen Fehlertoleranz und Ausfallsicherheit.
Grundbegriffe
Im Folgenden werden die wesentlichen Begrifflichkeiten aus der Kafka-Welt eingeführt und die grundlegenden technischen Zusammenhänge dargelegt.
Logische Ebene
Der Nachrichtenaustausch wird in Apache Kafka über Topics realisiert. Ein Topic kann man sich wie einen benannten Kommunikationskanal vorstellen, in den Nachrichten eines Datenstroms bzw. zu einem Thema hineingeschrieben werden. Diese können anschließend wieder ausgelesen werden. Die Nachrichten werden dabei standardmäßig für 7 Tage persistiert. Dadurch entsteht eine Entkopplung zwischen schreibenden und lesenden Clients. Kafka arbeitet nach dem Publish-and-Subscribe-Modell. Clients, die Nachrichten erzeugen und in Topics hineinschreiben, werden Producer genannt. Clients, die Nachrichten aus einem Topic lesen, übernehmen die Rolle des Consumers (vgl. Abbildung 1).
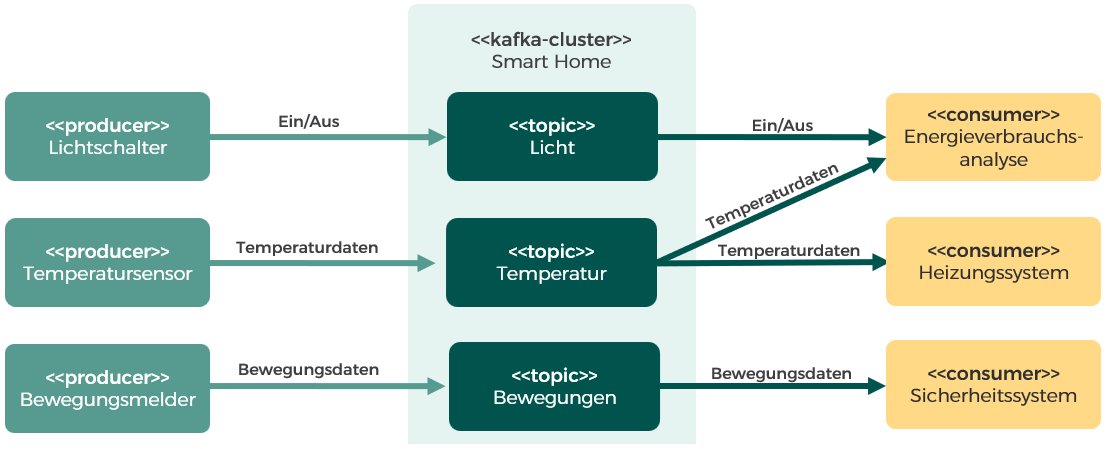
Abbildung 1: Produzenten, Konsumenten und Topics am Beispiel eines Smart-Home-Systems
Über Consumer Groups lassen sich zudem Consumer zusammenschließen, sodass die Nachrichten eines Topics parallel abgearbeitet werden – jede Nachricht wird dabei idealerweise aber nur einmal (und nicht mehrfach) durch Konsumenten der gleichen Gruppe verarbeitet.
Physische Ebene
Apache Kafka ist für den Cluster-Betrieb ausgelegt. Unter der Haube besteht ein Apache-Kafka-Cluster aus einem Verbund von Nodes, auf denen Kafka läuft, die Broker genannt werden. Ein Broker speichert und verwaltet die Nachrichten von Topics in Partitionen. Eine Partition ist ein Append-Only-Log, in das Nachrichten immer nur am Ende angefügt werden (vgl. Abbildung 2). Das Lesen erfolgt ebenfalls sequenziell: Hierzu wird für jeden Consumer bzw. jede Consumer Group ein Offset verwaltet, um nachzuhalten, an welcher Stelle man sich gerade befindet.
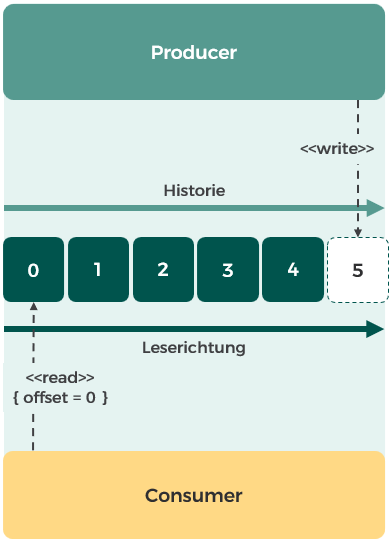
Abbildung 2: Lesen aus und Schreiben in das Log einer Partition durch Producer und Consumer
Ein Topic wird auf physischer Ebene in eine konfigurierbare Anzahl an Partitionen aufgespalten und selbstständig von Kafka möglichst gleichmäßig über die verfügbaren Broker verteilt (vgl. Abbildung 3). Ein Broker-Knoten kann dabei sowohl keine, eine als auch mehrere Partitionen eines Topics verwalten. Dies ist einer der Schlüsselfaktoren für die hohe Verarbeitungs-geschwindigkeit von Kafka, da somit mehrere Consumer aus mehreren Partitionen gleichzeitig lesen können.
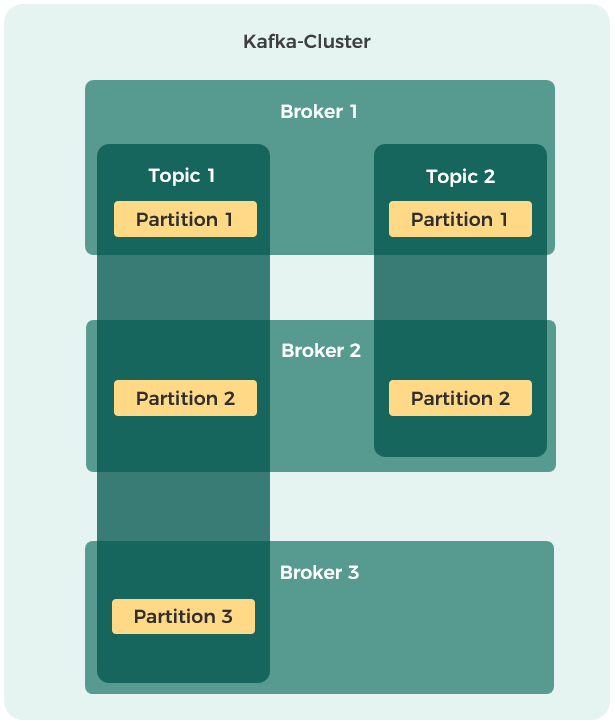
Abbildung 3: Beispielhafte Verteilung von Topics und zugehörigen Partitionen auf Broker im Cluster
Partitionen werden zudem bei Bedarf auch repliziert. Über einen konfigurierbaren Replikationsfaktor kann je Topic angegeben werden, auf wie vielen Brokern jede zugehörige Partition redundant gespeichert werden soll. Auch hier übernimmt Apache Kafka die Verteilung. Die Replikationsfähigkeit bildet die Grundlage für die Ausfallsicherheit durch redundante Datenhaltung in Kafka.
Event Streaming und Echtzeitdatenverarbeitung
Apache Kafka ist – wie eingangs erwähnt – eine Event-Streaming-Plattform und wird für die Echtzeitdatenverarbeitung eingesetzt. Was bedeutet das genau?
Event
Ein Event wird ausgelöst, wenn etwas passiert ist. Dies kann z. B. der Fall sein, wenn ein Lichtsensor einen neuen Wert gemessen, jemand auf eine Schaltfläche geklickt oder eine Bestellung aufgegeben hat. Events unterliegen in der Regel einer zeitlichen Ordnung. Informationen über Events können einen Zeitstempel, Metadaten sowie weitere im konkreten Kontext relevante Werte beinhalten.
Streaming
Beim Streaming werden Daten kontinuierlich und ununterbrochen weiterverarbeitet (vgl. Abbildung 4). Die Verarbeitung erfolgt demnach sofort, wenn neue Daten eintreffen. Man spricht hierbei von Daten in Bewegung (Data in Motion). Misst bspw. ein Lichtsensor einen Wert, so wird sofort ein Event erzeugt und eine adäquate Weiterverarbeitung durchgeführt (z. B. Rollladen herunterfahren).
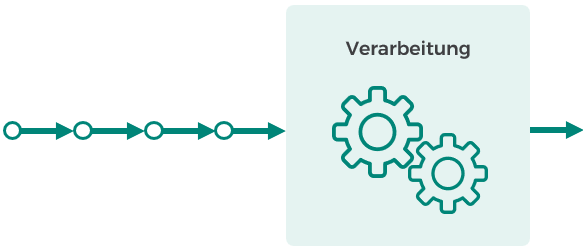
Abbildung 4: Streaming (Data in Motion)
Dies steht im Gegensatz zu traditionellen Ansätzen, bei denen Daten zunächst in einer Datenbank, einem Data-Warehouse oder einem Data Lake gespeichert (Data at Rest) und später gesammelt weiterverarbeitet werden (sog. Batch Processing, vgl. Abbildung 5). Ein Beispiel hierfür ist eine Bank, die tagsüber eingereichte Überweisungen sammelt und später gebündelt nächtlich ausführt.

Abbildung 5: Batch Processing (Data at Rest)
Kafka als Event-Streaming-Plattform
Echtzeitdatenverarbeitung wird immer mehr zu einem zentralen Dreh- und Angelpunkt in heutigen Geschäftsmodellen. Um konkurrenzfähig zu bleiben, müssen Unternehmen anfallende Daten sofort analysieren und verarbeiten. Bei Online-Zahlungsdiensten wie PayPal reicht es nicht aus, im Nachhinein zu prüfen, ob eine Transaktion betrügerisch war. Denn ansonsten ist das Geld bereits ausgezahlt, bevor der Betrug erkannt ist. Kafka kann in solchen Fällen als Event-Streaming-Plattform seine Trümpfe ausspielen.
Frameworks
Kafka Streams und Kafka Connect sind wichtige Frameworks im Kafka-Kosmos:
Kafka Streams ist ein Framework, das in eigene Anwendungen integriert werden kann. Es ermöglicht das Auslesen von Daten aus Kafka (Quell-Topic), ihre Verarbeitung sowie das Zurückschreiben (Ziel-Topic) nach Kafka.
Kafka Streams bietet z. B. bereits Konzepte für Aggregationen, Fensteroperationen (sog. Windowing), Zustandsverwaltung (mittels State Stores), Fehlerbehandlung (automatische Wiederholungsversuche und Status-Wiederherstellung mittels State Stores) an.
Kafka Connect ist ein Framework zur einfachen Integration von externen Systemen mit Kafka. Es stellt eine Vielzahl von vorgefertigten Open-Source-Konnektoren (Apache 2.0-Lizenz) für verschiedene Arten von Datenquellen und Datensenken bereit, die für den Einsatz nur noch entsprechend konfiguriert werden müssen – z. B. Datenquellen und -senken für JDBC (Java Database Connectivity), Elasticsearch, MQTT (Message Queuing Telemetry Transport), HDFS (Hadoop Distributed File System) oder Cassandra, um nur einige zu nennen.
Darüber hinaus gibt es kommerzielle Konnektoren von Confluent und anderen Anbietern inkl. Enterprise Support – z. B. für S3 (Simple Storage Service), Salesforce, SAP HANA (High-Performance Analytic Appliance), Google BigQuery oder Snowflake. Kafka Connect läuft als eigenständiges Tool, kann horizontal skaliert werden und unterstützt bei der Fehlerbehandlung – z. B. mittels DLQs (Dead-Letter-Queues) oder Retry-Mechanismen.
Schnittstellen
Da Kafka auf maximale Effizienz in der Performance ausgelegt ist, stellt es serverseitig keine HTTP-REST-Schnittstelle zur Verfügung. Stattdessen wird ein speziell entwickeltes Binärprotokoll für die Kommunikation mit Kafka verwendet. Deshalb müssen Anwendungen, die mit Kafka interagieren möchten, von Kafka vorgegebene Bibliotheken importieren. Diese stellen der Anwendungsentwicklerin/dem Anwendungsentwickler verschiedene APIs bereit, die im Folgenden kurz beschrieben werden.
Hinweis: Es gibt offiziell unterstützte Bibliotheken für Java, Scala, .NET, Python und Go sowie Community-getriebene Projekte, sodass auch ein Einsatz aus z. B. C++, Ruby, Rust, PHP etc. möglich ist. Findet sich für die eigene Anwendung keine entsprechende Bibliothek, so bieten spezielle REST-Proxys die Möglichkeit, über HTTP mit Kafka zu kommunizieren, was allerdings zu Effizienzverlusten führt.
| API | Beschreibung |
|---|---|
| Producer API | Diese API wird von Anwendungen verwendet, um Nachrichten bzw. Events an Kafka zu senden. |
| Consumer API | Diese API wird von Anwendungen verwendet, um Nachrichten bzw. Events aus Kafka zu lesen. |
| Admin API | Diese API wird von Anwendungen verwendet, um administrative Aufgaben wie z. B. das Erstellen, Bearbeiten und Löschen von Kafka-Topics durchzuführen. |
| Streams API | Die Streams API gibt dem Entwickler auf Programmierebene Zugriff auf das Framework und unterstützt bei der Implementierung von Transformations-, Join- und Aggregationsoperationen mit Only-Once-Semantik … |
| Connect API | Die Connect API bietet eine Schnittstelle zur Entwicklung benutzerdefinierter Konnektoren … |
Schema Registries
Aus Sicht von Apache Kafka sind Nachrichten nichts anderes als Binärdaten bzw. Byte-Arrays. In der Praxis beherbergt eine Nachricht in der Regel mehrere Informationen, die für eine einfache systemübergreifende Verarbeitung üblicherweise entsprechend strukturiert werden. Die Struktur einer solchen Nachricht wird über ein Schema definiert, sodass ein konsistenter Austausch zwischen Produzenten und Konsumenten sichergestellt ist. Als Datenformate werden häufig Avro, JSON oder Google Protobuf eingesetzt.
Es ist gerade in größer werdenden Systemen eine gute Idee, frühzeitig Schemas explizit zu definieren und in einer Schema Registry zu hinterlegen (Confluent Schema Registry oder z. B. Karapace als Open-Source-Alternative). Nachrichtenerzeuger (Producer) speichern neue Schemas automatisch in der Schema Registry und fügen die Schema-ID als Metadatum der auf zugehörige Art und Weise serialisierten Nachricht hinzu. Ein Nachrichtenempfänger (Consumer) kann dann über die Schema-ID aus den Metadaten der Nachricht das entsprechende Schema aus der Schema Registry abrufen und entsprechend deserialisieren. Schema Registries sind gerade auch im Hinblick auf Schema-Evolution von Belang, um z. B. eine Vorwärtskompatibilität oder Rückwärtskompatibilität hinsichtlich der Änderung von Schemas zu ermöglichen.
Unser Apache Kafka-Beratungsangebot umfasst:
Infrastrukturberatung
Ob in der Cloud oder On-Premises: Wir helfen Ihnen beim Setup Ihrer Kafka-Instanz mit Docker, Podman oder Kubernetes – unter Linux oder Windows.
Architekturberatung
Die frühzeitige Klärung von Fragen rund um Themen des Cluster-Designs wie die Skalierung, Partitionierung, Hochverfügbarkeit oder Replikation ist entscheidend für den Erfolg Ihres Projekts. Sprechen Sie uns an!
Datenintegration & ETL-Strategien
Wir integrieren Ihre Datenquellen, Services und Drittsysteme nahtlos in Kafka – von relationalen Datenbanken über Data Lakes bis hin zu SaaS-Anwendungen. Ob mit Kafka Connect, Kafka Streams oder ksqlDB: Wir unterstützen Sie beim Aufbau robuster, skalierbarer Data Pipelines für eine zukunftssichere Event-Streaming-Architektur.
Event-getriebene Architekturen (EDA)
Wir helfen Ihnen beim Umstieg auf skalierbare, event-getriebene Architekturen mit Apache Kafka – ideal für moderne Microservices-Landschaften. Unsere Experten begleiten Sie bei Event-Design, Domänenmodellierung und Umsetzung – praxisnah und zukunftssicher.
Anwendungsfälle für Apache Kafka
Apache Kafka ist deshalb so nützlich, weil es eine Vielzahl von Datenquellen und -senken unterstützt und vielfältig einsetzbar ist. Der folgende Abschnitt soll einen Überblick über die Anwendungsfälle – sowohl aus technischer als auch aus fachlicher Sicht – geben.
Abbildung 6 fasst zudem verschiedene Möglichkeiten der Nutzung von Kafka mit Fokus auf Datenquellen und -senken (ohne Anspruch auf Vollständigkeit) visuell zusammen:
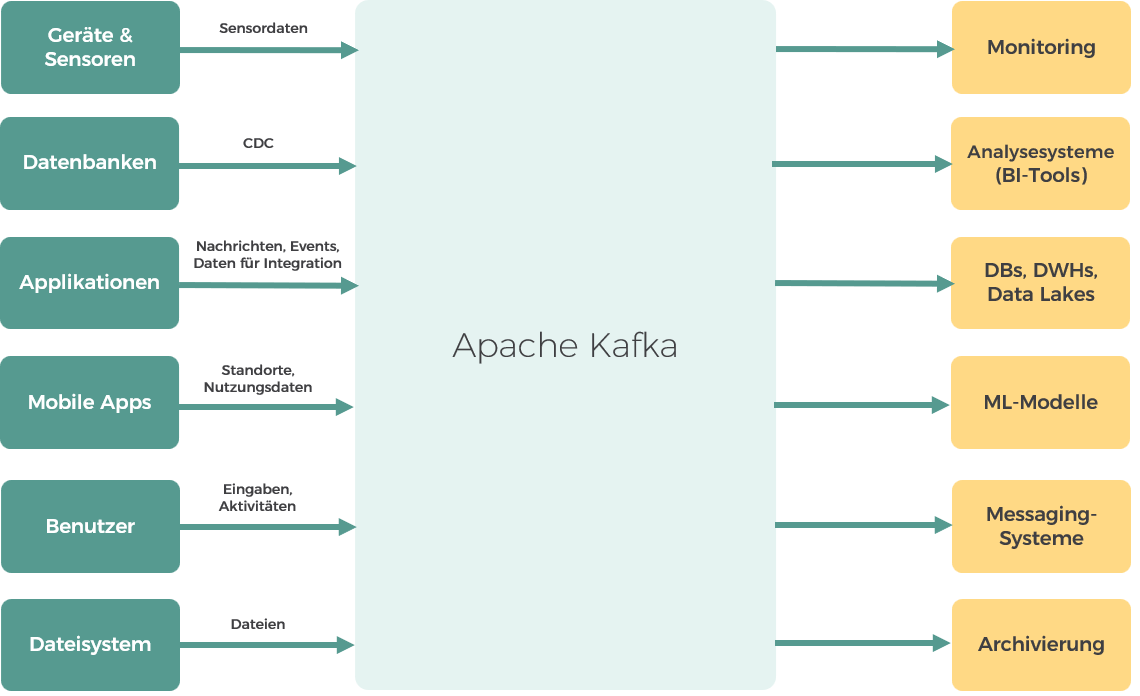
Abbildung 6: Anwendungsmöglichkeiten von Apache Kafka
Einsatzmöglichkeiten von Apache Kafka aus technischer Sicht
Datenintegration und -verteilung: Apache Kafka wird häufig für die Datenintegration und -verteilung eingesetzt. Häufig wird es in diesem Zusammenhang auch als zentrale Datendrehscheibe oder als Data Hub bezeichnet. In Kafka werden hierbei die Daten aus verschiedenen Datenquellen eingespeist, miteinander verwoben und weiter verteilt. Datenanliefernde und -abholende Systeme agieren dabei völlig entkoppelt voneinander. Auf diese Weise können leicht neue Systeme in die Architektur integriert werden.
Event Driven Architecture: Apache Kafka eignet sich hervorragend zum Einsatz in einer EDA (Event-Driven Architecture). Ein ereignisproduzierender Service propagiert dabei Ereignisse bzw. zugehörige Nachrichten an ein entsprechendes Topic in Kafka, auf welche Konsumenten reagieren können (reaktional). Konsumenten sind hierbei nicht verpflichtet, die jeweiligen Ereignisse zu verarbeiten – sie können diese auch ignorieren. Hierdurch wird eine starke Entkopplung erreicht (choreographierte Kommunikation), denn der Ereignisauslöser muss nicht wissen, was mit dem Ereignis geschieht.
Event Sourcing: Event Sourcing kann als Spezialfall der EDA aufgefasst werden. Der aktuelle Systemzustand wird hierbei durch die Sequenz der aufgetretenen Ereignisse definiert. Die Ereignisse werden persistiert und dienen als primäre Quelle der Wahrheit. Der Zustand eines Services lässt sich damit für jeden Zeitpunkt in der Historie nachvollziehen und auch wiederherstellen.
Aktionale Kommunikation zwischen Microservices: Apache Kafka kann in einer Microservice-Architektur auch aktional eingesetzt werden. In diesem Fall ist der Empfänger der Nachricht verpflichtet, eine Aktion auszuführen – optional kann der Produzent eine Antwort verlangen. Warum sollte man Kafka dafür einsetzen, wenn es für diesen Zweck etablierte Techniken wie z. B. REST oder gRPC (gRPC Remote Procedure Call) gibt? Der Einsatz von Kafka ist besonders in Szenarien anzuraten, in denen ein hoher Datendurchsatz erforderlich ist. Zudem lassen sich Nachrichten in Kafka puffern. Aktionale und reaktionale Nutzungen von Kafka können auch in einer Architektur kombiniert werden, um die jeweiligen Stärken auszuspielen.
Log Aggregation und Monitoring: Häufig wird Apache Kafka auch für Log Aggregation und Monitoring eingesetzt. Das ist insbesondere für Unternehmen interessant, die eine Vielzahl verschiedener Systeme einsetzen, die klassische Logs produzieren. Log Aggregation ermöglicht es, die so verteilten Logs aus den verschiedenen Quellen zusammenzuführen, in Verbindung zu setzen, zu analysieren und zu überwachen. Kafka spielt hier insbesondere dann seine Stärken aus, wenn große Datenmengen in Echtzeit verarbeitet werden müssen und eine schnelle Reaktion erforderlich ist. Dabei werden die Log-Daten, die von Applikationen und Servern erzeugt werden, mithilfe von sog. Log-Shippern wie Filebeat oder Logstash in ein einheitliches Format (z. B. JSON) gebracht und an Apache Kafka als zentrale Log-Plattform übergeben.
Werden bspw. Access Logs analysiert, kann eine Mustererkennung stattfinden, sodass beim Vorliegen von Anomalien gezielt auf entsprechende Szenarien reagiert werden kann (z. B. durch Alerting auf Basis von Prometheus). Durch Anschluss von Elasticsearch und Tools wie Kibana oder Grafana können die Logs bei Bedarf zusätzlich langfristig durchsuchbar gemacht werden.
Migration und Datensynchronisation: Gerade bei der Migration größerer Softwareplattformen besteht oft der Wunsch, die neue und alte Systemlandschaft (zumindest in Teilen) parallel zu betreiben. Kafka kann hier eingesetzt werden, um die Welten miteinander zu verbinden und Daten in Echtzeit zu synchronisieren, sodass Systembrüche weitestgehend vermieden werden oder zumindest weniger spürbar sind. Hierbei sind insbesondere auch CDC-Tools (Change Data Capture) wie Debezium relevant. Sie spielen eine zentrale Rolle, wenn die alte Welt hauptsächlich aus Datenbanken besteht und ansonsten keine andere Möglichkeit bietet, Datenänderungen abzufangen und weiter zu propagieren.
Internet of Things: Als Event Streaming Plattform ist Apache Kafka prädestiniert für die Verarbeitung von Geräte- und Sensordaten im IoT-Kontext (Internet of Things).
Einsatzmöglichkeiten von Apache Kafka aus fachlicher Sicht
Betrugserkennung: Kafka kann im Finanzsektor bei der Betrugserkennung helfen. Durch die Echtzeitverarbeitung können Transaktionen gestoppt werden, bevor Schaden entsteht. Betrugserkennungsmodelle können direkt in die Streaming-Verarbeitung integriert werden.
E-Commerce: Kafka ermöglicht in E-Commerce-Anwendungen eine schnelle personalisierte Reaktion auf Kundeninteraktionen (Klicks, Käufe, Produktaufrufe, Prozessabbrüche), sodass das Kundenerlebnis verbessert und Conversion Rates gesteigert werden können.
Predictive Maintenance: Im Rahmen von Predictive Maintenance können Sensor- und weitere Maschinendaten mithilfe von Kafka in Echtzeit analysiert und Ausfälle frühzeitig erkannt werden. Dies führt zu optimierten Wartungsintervallen und geringeren Kosten.
Verkehrssteuerung: Im Rahmen der intelligenten Verkehrssteuerung in Städten ermöglicht Kafka die Auswertung der Daten von Sensoren oder Kameras in Echtzeit, sodass sofort auf den aktuellen Verkehrsfluss reagiert werden kann. Dies kann z. B. in die Anpassung von Ampelschaltungen, Änderung von Geschwindigkeitslimits oder die dynamische Sperrung von Spuren münden. Dadurch können sowohl Staus als auch unnötige CO2-Emissionen reduziert werden.
Abgrenzung zu anderen Technologien
Wie grenzt sich Kafka von anderen Technologien oder Infrastrukturkomponenten ab? In diesem Abschnitt wird durch Gegenüberstellung mit ebenjenen beleuchtet, wo der Schwerpunkt von Kafka liegt bzw. welche Aspekte auch explizit ausgeklammert werden und warum.
Message Broker vs. Kafka
Message Broker wie z. B. RabbitMQ oder ActiveMQ dienen vorrangig dem Zweck, Nachrichten zwischen Sender und Empfänger zu vermitteln. Der Hauptanwendungsbereich liegt somit auf der Kommunikation zwischen verteilten Systemen. Dabei unterstützen Message Broker sowohl das Punkt-zu-Punkt- als auch das Publish- und Subscribe-Modell. Kafka legt ausschließlich Letzteres zugrunde. Sowohl Kafka als auch Message Broker lassen sich horizontal skalieren, wenngleich bei Message Brokern häufig Grenzen vorhanden sind. Kafka ist dagegen darauf ausgelegt und überdies für die Verarbeitung großer Datenmengen entworfen worden. Standardmäßig persistiert Kafka alle Nachrichten zumindest zeitweise in seinen Logs, während bei Message Brokern Nachrichten eher standardmäßig beim Lesen gelöscht werden.
Kafka ist optimiert für einen hohen Datendurchsatz bei sehr niedriger Latenz. Dies spiegelt sich auch in den eingesetzten Protokollen wider: Kafka setzt ein proprietäres, auf Datendurchsatz optimiertes Binärprotokoll ein, während Message Broker gängige Standards wie AMQP, MQTT oder STOMP implementieren. Message Broker eignen sich somit eher für Projekte, bei denen Nachrichten kurzlebig sind und Anforderungen wie Skalierbarkeit und Datendurchsatz eine untergeordnete Rolle spielen. Ob im konkreten Fall Kafka oder ein Message Broker zum Einsatz kommen sollte, hängt von den individuellen Anforderungen ab.
Kafka als persistenten Speicher nutzen?
Sowohl Datenbanken als auch Kafka können Daten dauerhaft speichern, sodass sie später wieder abgerufen werden können. Die Speicherung erfolgt dabei allerdings in unterschiedlicher Form, da unterschiedliche Einsatzzwecke verfolgt werden: Datenbanken fokussieren auf langfristige Speicherung (Data at Rest) und spätere Datenverarbeitung, Kafka auf den Datenaustausch zwischen Systemen und zeitnaher Verarbeitung von Data in Motion.
Während die häufig eingesetzten relationalen Datenbanken den aktuellen Zustand strukturiert in Tabellen speichern, speichert Kafka Events in ihrer zeitlichen Abfolge in Logs. Im Gegensatz zu Tupeln in Datenbanken sind Events in Kafka grundsätzlich unveränderlich (immutable), sodass diese Eigenschaft auch revisionssichere historische Datenanalysen ermöglicht.
Klassische Datenbanksysteme sind für komplexe Ad-hoc-Abfragen im Rahmen von OLAP (Online Analytical Processing) und mittels SQL (Structured Query Language) vielfach der etablierte Weg. Aber auch Kafka-Topics können mithilfe von ksqlDB, das auf Kafka Streams basiert, derart abgefragt werden: Dazu muss im Vorfeld einmalig eine materialisierte Sicht aufgebaut werden, die in einer Mischform aus den Sprachen DDL (Data Definition Language) und Streaming SQL definiert wird.
ksqlDB verwendet intern RocksDB als effizienten Key-Value-Store, um berechnete Werte zu speichern (z. B. Aggregationen). Treffen neue Daten ein, so wird die Materialized View automatisch aktualisiert. Mit einer Pull Query können Daten dann später klassisch per SQL abgefragt werden. Bei einer Push Query, die auf Basis von Streaming SQL formuliert wird, werden die Ergebnisse der Abfrage kontinuierlich aktualisiert, d. h. sobald neue Daten in das zugrundeliegende Topic geschrieben werden.
In einer Datenbank bleiben Daten bis zur expliziten Löschung erhalten. In Kafka ist keine gezielte Löschung einzelner Nachrichten vorgesehen. Vielmehr wird Datenlöschung in Kafka über Cleanup Policies gesteuert (vgl. folgende Tabelle). Beide Policies können auch gleichzeitig aktiv sein.
| Cleanup Policy | Beschreibung |
|---|---|
| Delete (Standard) | Nachrichten werden gelöscht, sobald eine der beiden folgenden Regeln greift (wobei keine, eine oder beide gleichzeitig aktiviert sein können): Time-based Retention Nachrichten werden nur für eine bestimmte Zeit (die konfigurierbar ist) persistent gespeichert und danach automatisch von Kafka gelöscht. Size-based Retention Alte Nachrichten werden automatisch von Kafka gelöscht, wenn das gesamte Topic eine bestimmte Größe (die konfigurierbar ist) überschreitet. Man spricht von einer Unlimited Retention, wenn die Konfiguration derart angelegt ist, dass weder zeit- noch größenbasierte Löschungen vorgenommen werden. |
| Compact | Für einen bestimmten Partition Key (Schlüssel, auf dessen Basis eine Einordnung in eine Partition vorgenommen wird) wird immer nur die neueste Nachricht gespeichert. Dies lässt sich z. B. dafür nutzen, wenn nur die aktuelle Version eines Datensatzes in Kafka vorgehalten werden soll. |
Im Hinblick auf Datenkonsistenz sollte bedacht werden, dass Kafka als hochskalierbares, verteiltes System nur Eventual Consistency anbietet. Falls hohe Konsistenz wichtig ist, kann ein Datenbanksystem diese auf Basis der ACID-Prinzipien (Atomacity, Consistency, Isolation, Durability) garantieren. Es gilt allerdings auch als Anti-Pattern, Nachrichtenaustausch zwischen Systemen über eine Datenbank zu betreiben (siehe unterschiedliche Einsatzzwecke von Kafka und DBs in der Einleitung zu diesem Abschnitt).
Ist es nun also eine gute Idee, Apache Kafka als Ersatz für eine Datenbank zu verwenden? Häufig wird Apache Kafka als Single Source of Truth eingesetzt, in welcher die Events unveränderlich dauerhaft verbleiben. Sie dienen dann dazu, auf Systeme übertragen zu werden, die für die Verarbeitung bzw. Abfrage der Daten im jeweiligen Einsatzkontext optimiert sind – sei es eben eine relationale Datenbank, die per ORM (Object-Relational Mapping) an eine Anwendung angebunden ist, oder ein Elasticsearch-Index für eine unscharfe Suche oder ein Redis-Cache, der Zugriffszeiten auf häufig benötigte Datenobjekte optimiert.
Fazit
Apache Kafka ist in vielen Szenarien einen Blick wert und vielseitig einsetzbar. Kafka wird primär in modernen, skalierbaren Echtzeitdatenverarbeitungssystemen eingesetzt und spielt eine gewichtige Rolle in Software-Architekturen rund um Microservices, EDAs sowie Big-Data-Lösungen. Deshalb gehört es in den Werkzeugkasten eines jeden Software-Architekten, der mit sachgemäßem Einsatz von Open-Source-Komponenten Mehrwerte generieren möchte.
Aufgrund seiner hohen Beliebtheit finden sich viele nützliche Informationen und Lösungen zu spezifischen Problemen im Web. Als Apache-Top-Level-Projekt ist es zudem sehr gut dokumentiert. Erste Schritte mit Kafka können schnell auf Basis des zur Verfügung gestellten Docker-Images angegangen werden. Die Grundlagen von Kafka sind relativ einfach zu verstehen. Allerdings wird die Lernkurve rasch steiler, wenn es um Skalierung, Fehlertoleranz und Performance-Optimierung – insbesondere im Produktiveinsatz – geht.
Sie nutzen bereits Messaging-Lösungen und überlegen, ob Apache Kafka das richtige System für Ihre Anforderungen ist? Dann sprechen Sie mit uns – wir teilen gerne unsere Projekterfahrungen und unterstützen Sie bei der Bewertung.

* Pflicht für alle Anfragen zu unseren Angeboten.
Weiterführende Links

